数据/模型目录
一个统一治理数据与 AI 模型的目录,为每个团队提供可信赖的唯一真源。
概念架构图
核心优势
数据与模型统一治理
数据目录与 ML 模型注册表合二为一。在一个目录中集中管理数据资产与 AI 模型,为整个组织建立真正的唯一真源 (SSOT)。
自动同步 10 种数据源
自动从 Hive、Impala、Kudu、Trino、StarRocks、Greenplum、PostgreSQL、MySQL、Oracle 及 MSSQL 收集元数据,持续更新模式、统计和血缘信息。
跨平台列级血缘
通过 SQL 解析 (sqlglot) 在数据集和列级别实现自动端到端血缘追踪,支持基于查询、基于流水线以及手动血缘。
兼容 MLflow Unity Catalog
完全兼容 MLflow Unity Catalog API —— 现有 MLflow 工作流无需改动即可使用。配备基于 OCI、部署于 S3/MinIO 的模型存储。
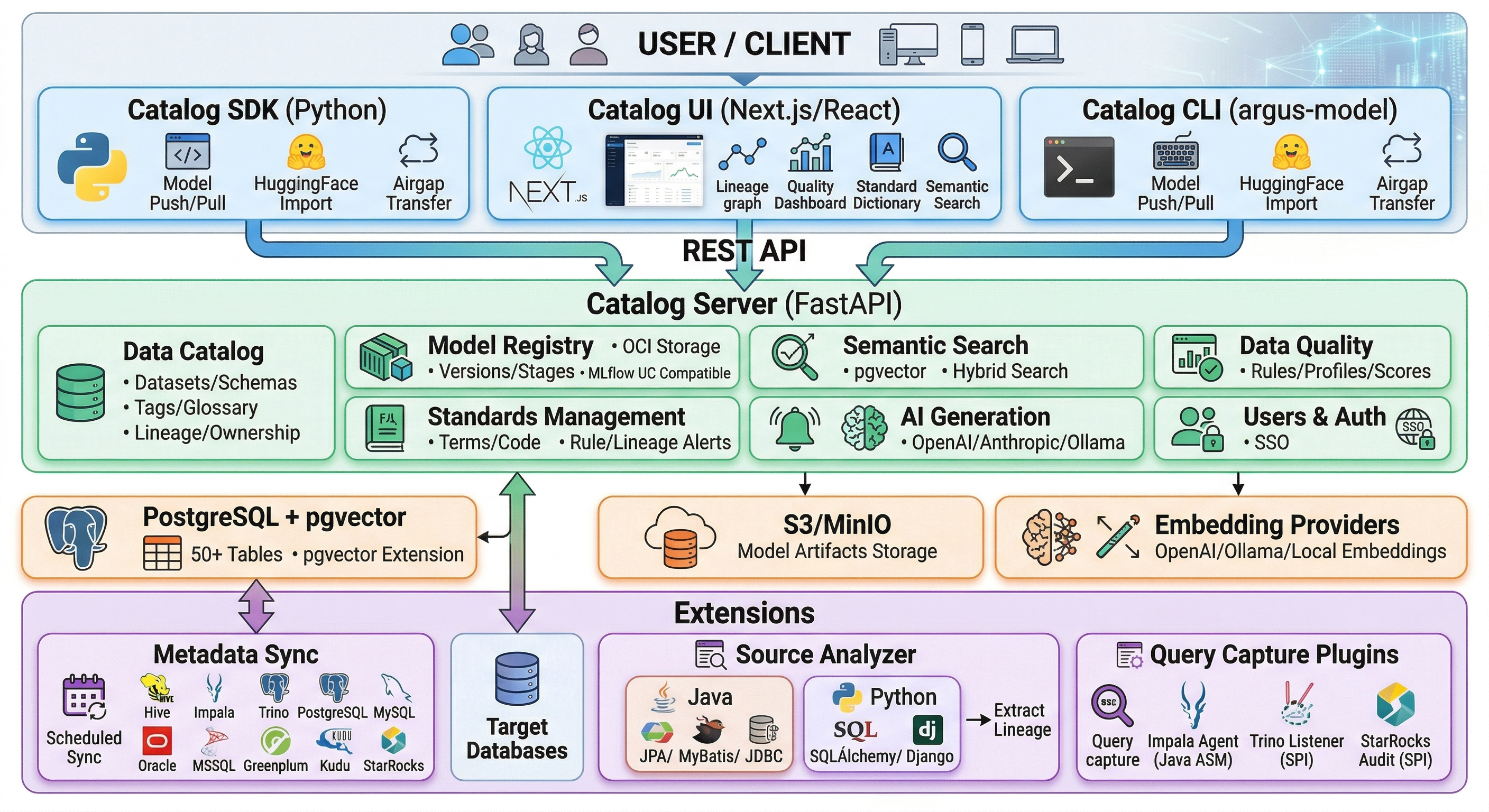
平台架构
端到端的目录平台,Catalog UI、Server、扩展组件与 SDK 无缝协作。
主要功能
涵盖数据治理、ML 模型管理及离线环境部署支持等企业级目录所需的全部能力。
多平台数据目录
基于 URN 的数据集身份识别、通过快照追踪模式变更历史,在同一目录中统一管理标签、术语与所有权。
跨平台血缘
在数据集和列级别实现端到端血缘追踪,支持基于查询、基于流水线以及手动血缘来源。
ML 模型注册表
兼容 MLflow Unity Catalog API 的模型注册表,基于 OCI 的 Artifact 存储于 S3/MinIO,并提供版本与阶段管理。
数据质量引擎
定义并执行 NOT_NULL、UNIQUE、MIN/MAX、REGEX、FRESHNESS、CUSTOM_SQL 等质量规则,并计算综合质量评分。
数据标准管理
管理标准字典、域、术语(含词素分析)、代码组与取值、术语到列的映射以及变更审计日志。
语义与混合搜索
结合 pgvector 向量嵌入与关键词搜索,支持以自然语言发现数据集与模型。
源代码分析
从 Java (JPA、MyBatis、JDBC) 与 Python (SQLAlchemy、Django) 源代码中自动发现表和列的访问模式。
离线模型传输
面向离线隔离的安全环境,提供线上拉取 → USB 传输 → 离线导入的工作流。